
by Max Denker
Just as humans need air to live and grow, artificial intelligence needs data to live and grow. The more quality data artificial intelligence (AI) can digest, the better it can learn and adapt to meet the needs of its users. But what if this life-critical data is too sensitive, limited, or time consuming to collect? This is where synthetic data comes in.
What is synthetic data?
Before we get into the details of synthetic data (SD), it is important to understand two commonly paired pieces of terminology – artificial intelligence (AI) and machine learning (ML). AI is the theory and development of computer systems performing tasks which previously required human intelligence. ML is a subcategory of AI. ML consists of computer programs that fit a model or recognize patterns from data without being explicitly programmed and with limited or no human interaction.
To understand SD we must first start with real data and its inherent problems. As I alluded to above, real data can be extremely challenging, cumbersome, and risky to work with. Think about your personal health or financial information – your medical history, social security number, prescriptions, credit score, savings information, etc. – very private and sensitive data that must be held by organizations with intense security and compliance to government regulations. It can take six months or more to gain approval to utilize the data for research, innovation, or testing… even within the organization who holds the data!
Not only is this time consuming, but once you are given the greenlight to use the data, you must safeguard the information. Lastly, trends that businesses want to investigate, such as fraud or rare disease, are limited in these real datasets due to the nature of their less frequent occurrences. In the end, this inability to quickly gain vast amounts of data to build AI hinders industries and companies from reaching their full innovation and business potential.
This is why by 2024, 60% of data used to develop AI and analytics projects will be SD, and the SD generation market will be $1.16 billion by 2027, with is 48% CAGR from 2021.
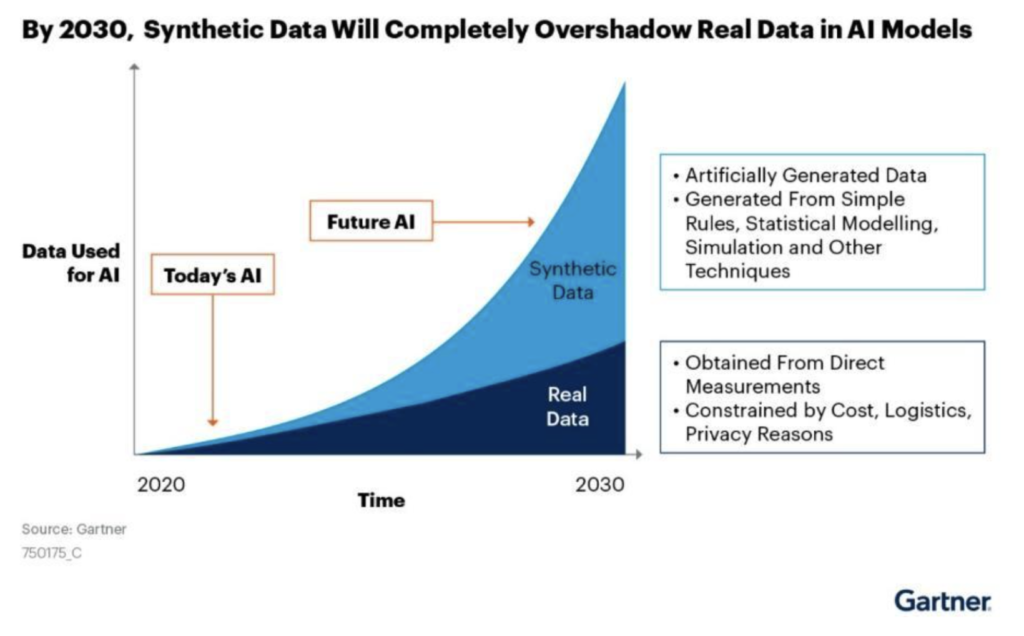
So, what is synthetic data? It is artificially created data by learning patterns and statistical properties of the real data, with the ability to automatically annotate the SD. More specifically, machine learning algorithms digest real data and use it to replicate the patterns while removing/limiting the sensitivity of it. While other generation methods exist and founders are coming up with unique ones, there are four main methods for generating this SD from real data.
Four main methods for generating synthetic data:
- Generative Adversarial Networks (GANs). A generator network takes random sample data to generate a synthetic dataset, while a discriminator evaluates the data to identify which came from the real dataset and which from the generator. These two networks continuously learn from each other (compete against each other) to improve that SD in an iterative process, with the generator trying to get better at fooling the discriminator.
- Variational Autoencoders (VAEs). An encoder network learns and compresses the original dataset into a latent distribution. The decoder network generates SD from the compression.
- Language Modeling. Networks learn the probability distributions/sequences of real data to predict the future sequences.
- Agent-based modeling (ABM). A model is created that explains observed behavior between agents, then reproduces random data using the same model.
If no data is available to start, data scientists can use rule-based synthesis and known distributions to create the SD. The output from all these methods is data artificially generated by AI that was trained on a real dataset to reproduce the statistical properties and distribution of the real data.
Now that we have created data, what type of data did we generate?
There are two types of data, structured and unstructured. Structured data is tabular, relational, highly specific. Unstructured data is not specifically organized, think image, video, and audio. Furthermore, there are three levels of synthetic data:

Now that we defined the levels of SD, it is important to know that SD is evaluated on three components:
- Utility – is the data fit for its defined use?
- Fidelity – how well does the SD statistically match the original data?
- Privacy – does the SD leak any sensitive information about the source data?
Depending on the use case/industry, the three evaluation characteristics will have different weights. But no matter which industry we look at, SD solves the real-data problem through security, speed, and scale. Utilizing SD reduces or eliminates the risk of exposing sensitive data. Because of this risk reduction, the speed to obtain data is greatly reduced due to elimination of roadblocks from privacy and security concerns. Furthermore, you can quickly train ML models on larger datasets, leading to faster training, testing, and deploying of AI solutions. Lastly, this speed and ability to generate mass data lends itself to greater expansion of the amount to analyze and ultimately the types and numbers of problems to solve.
Going deeper into these benefits, SD also helps facilitate simulating not yet encountered conditions or situations, preserves the multivariate relationship between variables, and gives flexibility to deliberately include and label corner/edge-cases that are rare but crucial to evaluate.
Limitations & Barriers to Synthetic Data
While there is great benefit and potential with synthetic data, there are some limitations and barriers. The quality of the SD is reliant on the original dataset – quality in, quality out. Which also means outliers may be missing. Something we’re seeing in SD generating companies is how their technology accounts for output control. Additionally, SD and its uses are emerging concepts, the user knowledge and acceptance are challenging to push through. Some of this stems from concerns that the SD is not as good as the real data, though most SD generator companies produce fidelity reports, which also leads to hesitation that high fidelity may not be privacy ironclad. Also, SD generation does require time and effort, though is easier and cheaper than acquiring real data. SD generation and utilization can also require advanced knowledge of AI. Last but not least, there is difficulty in creating high-quality SD for extremely complex systems.
Startups are finding ways to differentiate themselves on industry/utilization focus, accuracy and privacy of their SD, ease of use, and proprietary generation methods. I leave you with some questions to think about for the future. Which industries are ripe to gain the most from SD? In what novel ways can SD be used? What will be the differentiators among startups in generating SD and facilitating customers to use it?
If you’re building in the space or want to chat about synthetic data, reach out to me on LinkedIn and send me a note or contact us via the form below.
Sources: